518 Anomalies on Your Screen and Nothing Got Fixed
Most carbon accounting platforms detect data quality issues just fine. The problem is what happens after detection - 518 unresolved alerts with no prioritisation, no grouping, no investigation, and no workflow to fix them. Here's why anomaly detection without resolution is just a fancier way to ignore your data problems.
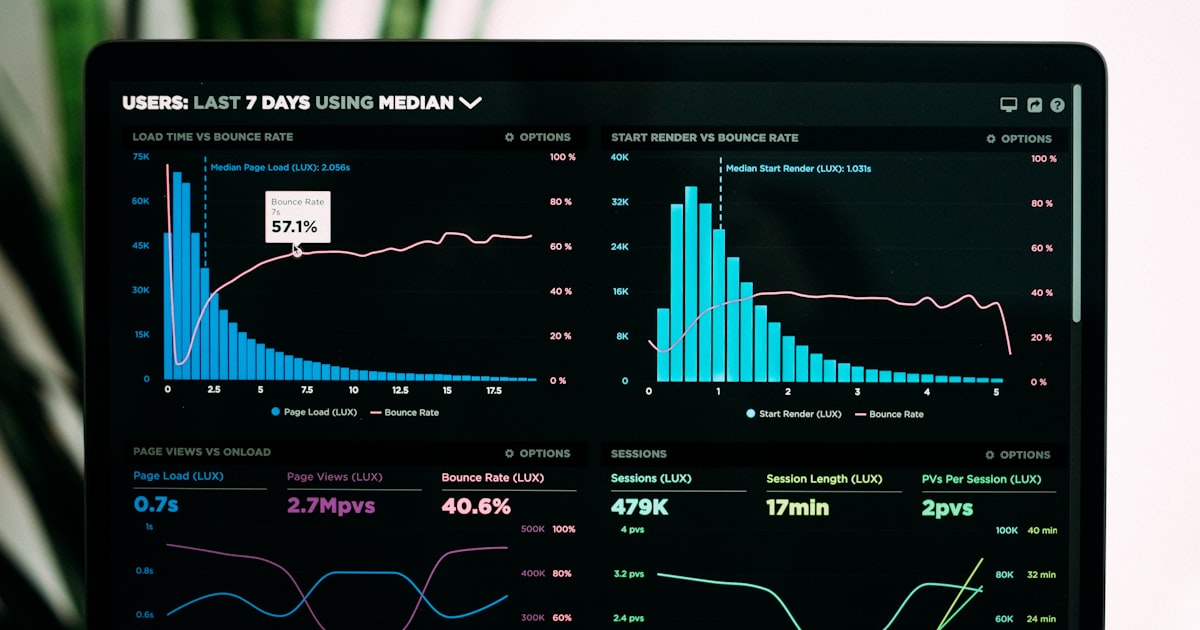
Open the data quality page. See 518 items. Close the page. Come back next quarter. See 534 items. Close the page again.
We've watched this exact pattern with sustainability managers using carbon accounting tools - including, honestly, early versions of our own. The anomaly detection module exists. It works. It catches things. And nobody acts on it because nobody knows where to start. A duplicate $47 fuel docket sits in the same list as a missing electricity quarter worth $180,000 in understated emissions. They look identical. Same red dot. Same urgency level.
The industry has a detection problem it's already solved. What it hasn't solved - what almost nobody is even talking about - is the resolution problem.
Detection was never the hard part
Every carbon accounting platform worth using has some form of data quality checking. Threshold rules, missing data alerts, duplicate flagging, statistical outlier detection. The technology isn't new and it isn't complicated. A z-score calculation that flags records more than 2.5 standard deviations from historical patterns is statistics, not magic.
And it works. The alerts are usually correct. That diesel consumption spike at a project site? Real anomaly. The electricity bill that's been missing for two months? Real gap. The five consecutive months of exactly 10,000 litres of diesel that look suspiciously like estimates? Probably are.
But "correct alert" and "useful alert" are different things.
A Harvard Business School study published in Nature Climate Change found that 74% of S&P 500 companies revised their emissions data at least once between 2010 and 2020. The net effect was 135 million tonnes of Scope 1 emissions that went unreported - roughly equal to the annual output of Venezuela. For comparison, only about 2% of US public companies restate financial data in any given year. Emissions data has a quality problem that financial data solved decades ago. And Australia isn't immune. The ANAO found that 72% of 545 NGER reports contained errors, with 17% containing significant ones.
The alerts exist. The data problems exist. But between those two facts sits a gap where nothing happens.
The five things wrong with how alerts work today
Here's what a typical anomaly detection screen actually looks like in practice, based on what we've seen across the tools available today.
Everything has the same weight. A duplicate $47 fuel docket and a missing quarterly electricity bill for a facility averaging 45,000 kWh per month sit in the same flat list. At Victoria's grid factor of 0.78 kg CO2-e/kWh, that missing quarter represents roughly 35 tonnes of unreported emissions - enough to shift your facility-level NGER figures. The fuel docket duplicate inflates your number by maybe 0.12 tonnes. One of these matters for compliance. The other is noise. But both get the same red icon.
Alerts say what, not why. "Threshold exceeded" tells you almost nothing. Did diesel consumption spike because the project mobilised heavy equipment for earthworks? Or did someone upload the same delivery docket twice from two different sources - once from the fuel card portal, once emailed from the site admin? These are completely different problems with completely different fixes. The first one might not be an error at all.
Related issues aren't grouped. Picture this: a supplier has been uploading duplicate invoices for the past eight months. That's one root cause generating 15-20 individual alerts. But the system shows you 15-20 separate problems. You investigate one. Fix it. Then discover the next one is the same issue. And the next. You've just spent an hour on what should have been a three-minute conversation with one supplier.
There's no way to fix anything from the alert. You identify the issue. Good. Now what? Open another tab. Find the source document. Compare it manually. Delete or correct the record. Recalculate the emissions. Update the audit trail. Most tools separate the "finding problems" function from the "fixing problems" function entirely, as if they're done by different people on different planets.
Noise never goes away. You looked at that round-number flag six months ago. Confirmed the reading against the source document - it really was exactly 10,000 litres because that's what the standing order delivers. The alert is still there. It'll be there next quarter too. And next year. It crowds out the alert you actually need to see: the electricity bill that stopped arriving three weeks ago for a facility that's still operational.
The result of all this isn't that data quality gets ignored because people don't care. It gets ignored because the system makes it exhausting to care.
What alert fatigue actually costs
This isn't just an annoyance. There's a real compliance cost sitting inside those unresolved alert lists.
The Clean Energy Regulator's 2025-26 compliance priorities state it plainly: "Accurate and timely reporting is critical to maintaining scheme data integrity. Repeated inaccuracies or failures to report on time will trigger compliance or enforcement action." They mean it. Beach Energy received an enforceable undertaking in July 2025 for "inadvertent misstatements" across multiple NGER reporting periods. Not fraud. Not deliberate misreporting. Errors nobody caught. The fix: three years of externally commissioned reasonable assurance audits at their own cost, plus an outside consultant to rebuild their control systems.
And it's about to get worse. NGER reporters are automatically pulled into ASRS Group 2 climate disclosures from the 2026-27 financial year. The same data that goes to the Clean Energy Regulator will now appear in your annual report, subject to ASSA 5010 limited assurance. Your NGER errors just gained a much bigger audience - investors, lenders, and the market.
Under Section 19 of the NGER Act, penalties for non-compliant reporting reach up to 2,000 penalty units ($660,000 at the current Commonwealth rate of $330 per unit). That's the stick. The real cost is the remediation: auditor fees, consultant engagements, resubmissions, and the internal time spent unravelling errors that could have been caught months earlier.
Consider a mid-size construction company running 30 active project sites. Each site generates electricity bills, gas invoices, diesel fuel dockets, and water statements monthly. That's roughly 120 documents per month, or 1,440 per year. If even 3% contain duplicates from overlapping data sources - fuel card portal, emailed receipts from site admins, accounts payable records - that's 43 duplicate records inflating your emissions by somewhere between 1.5% and 8% depending on the fuel type and volumes involved. Under AASB S2, your auditor is going to ask how you validated those numbers. "We had anomaly detection" isn't an answer if 518 alerts were sitting unresolved when the auditor showed up.
What should actually happen after detection
We've spent a lot of time thinking about this at Carbonly - partly because we've been building it, partly because our team spent years inside enterprise data systems at BHP, Rio Tinto, and Senex Energy watching the same data quality failures play out in mining and energy reporting.
The system shouldn't say "here are 518 things." It should say "3 things need your attention this week."
That means the work happens before the alert reaches a human. When the system detects something, it should already have investigated: pulled the source document, compared it against the historical pattern for that facility, calculated the emissions impact if the anomaly is a real error versus a legitimate change, and grouped it with any related issues.
Take duplicate invoice detection. A typical failure mode in construction carbon accounting: diesel fuel gets delivered to a project site. The delivery docket gets uploaded through the fuel card portal. Separately, the site admin emails the same docket to head office. Both enter the system. That's one issue - but in most tools, it shows up as two or more separate alerts, one per duplicated record.
What should happen instead: the system identifies that records X, Y, and Z all share matching supplier details, dates, and volumes. It groups them into a single issue. It calculates the combined emissions impact (say, 4.7 tonnes CO2-e of potential double-counting). It presents this as one item with evidence attached - here are the documents, here's the match, here's the impact. One click to confirm and resolve. Not an hour of forensic spreadsheet work.
Or take missing data detection. An electricity bill hasn't arrived for a project that's been averaging 45,000 kWh per month. Most systems flag this as "missing data for October." What should happen: the system recognises the gap, estimates the likely emissions impact based on the facility's 12-month rolling average (roughly 28-35 tonnes CO2-e depending on state), flags it as high priority because the impact exceeds the 5% materiality threshold that's standard in GHG accounting, and suggests the specific action: contact the utility provider, request a replacement bill, use the estimation methodology prescribed under NGER Method 1 in the interim.
That's the difference between alert generation and issue resolution.
Building trust between humans and automation
There's a progression that makes sense here, and it's the same progression that works in any domain where you're automating decisions that used to be manual.
In the beginning, the system watches and suggests. It flags the duplicate. It shows the evidence. But a human reviews every resolution, approves every correction, confirms every suppression. This is right. Nobody should hand over emissions data integrity to a black box on day one.
Over time, the system builds a track record. It's caught 200 duplicates. A human has confirmed 195 of them. The five it got wrong were all edge cases involving amended invoices that looked like duplicates but weren't. The system has learned from those corrections.
At that point, it makes sense for certain low-risk categories to be handled automatically. Verified exact duplicates where the documents are byte-identical? Auto-resolve, log the action, move on. Round-number flags where the source document has been checked and confirmed? Suppress for that supplier going forward. Missing data alerts for facilities that have been decommissioned? Clear automatically after verifying the decommission date.
But - and this matters - there should always be a way to pull back. An admin should be able to say "no, I want to see everything again" and revert to fully manual review at any time. Automation that you can't override isn't a tool. It's a liability.
We're honest about the fact that we haven't fully cracked the harder end of this. Consumption spikes that could be legitimate mobilisation or could be data errors - these still need human judgement. Scope 3 data quality, where you're dependent on supplier-provided numbers with no source documents to verify against, is still fundamentally messy. We're not going to pretend otherwise.
The anomalies that actually matter in construction and infrastructure
Since construction and infrastructure are where the highest-volume Scope 1 data flows live, here are the specific anomaly types that should be triaged as high priority, not buried in a 500-item list.
Duplicate fuel deliveries. Diesel is typically the single largest Scope 1 emission source for construction companies. We've written about the 10,000 fuel receipts problem before. When the same delivery enters the system from multiple sources - fuel card data, emailed dockets from site managers, accounts payable records - the inflation risk sits between 3% and 8% of total diesel emissions. At a fleet burning 800,000 litres per year (roughly 2,160 tonnes CO2-e), that's 65 to 170 tonnes of phantom emissions. Under NGER, where facility thresholds sit at 25,000 tonnes, that error alone could push a borderline facility over or under the reporting line.
Missing monthly data. If a project that's been consuming 45,000 kWh per month suddenly shows zero, something is wrong with the data - not the project. This needs to surface within days, not at year end when someone is compiling the NGER report. In Queensland at 0.67 kg CO2-e/kWh, that missing month is 30 tonnes. In Victoria at 0.78, it's 35 tonnes.
Consumption spike without operational context. Diesel at a project jumped 150% month-on-month. If it's mobilisation - new earthmoving equipment arriving on site - that's real consumption and your emissions go up legitimately. If it's a data entry error or a duplicate batch upload, your reported emissions are wrong. The system should be checking whether other operational indicators changed too (new purchase orders, equipment delivery records, project milestone updates), not just flagging the spike and walking away.
Persistent round numbers. Five consecutive months of exactly 10,000 litres of diesel is almost certainly an estimate, not a metered reading. Under NGER, estimated data must use prescribed estimation methods. Under AASB S2 assurance requirements, your auditor will want to know which figures are measured versus estimated. Round numbers that persist across multiple periods need to be either confirmed against source documents or flagged as estimates in the reporting.
Statistical outliers beyond explanation. A facility reporting emissions 2.5+ standard deviations from its 12-month rolling average deserves investigation. Not every outlier is an error - seasonal patterns, project phase changes, and weather all create legitimate variation. But the investigation should happen before reporting, not after.
Why this matters now more than before
Two things have changed in the Australian reporting environment that make unresolved data quality issues significantly more dangerous than they were even 18 months ago.
First, the NGER-to-ASRS pipeline. NGER data now feeds directly into mandatory climate disclosures under AASB S2. Scope 1 and 2 figures that were previously seen only by the Clean Energy Regulator will now appear in financial statements reviewed by investors, analysts, and lenders. A 5% inflation from undetected duplicates might not have triggered CER enforcement. But it will trigger questions from your auditor under ASSA 5010, and it could expose you to ACCC scrutiny if those inflated numbers flow into public emissions reduction claims.
Second, the bar for what constitutes "adequate controls" is rising. The CER's statement in Beach Energy's enforceable undertaking is telling: "While the NGER Act does not explicitly require corporations to implement such controls, their absence can lead to persistent and significant reporting inaccuracies." Read between the lines. They expect you to have systems in place. Not just data entry. Not just detection. Resolution.
Having 518 unresolved anomalies on your screen is, in a regulatory sense, evidence that you knew about data quality issues and did nothing about them. That's a worse position than not having anomaly detection at all.
Getting from 518 to 3
At Carbonly, we're rebuilding our anomaly detection module around this exact problem. Not better detection - better resolution. The goal is that when a sustainability manager opens the data quality screen, they see a prioritised list of issues, not a dump of every alert the system has ever generated.
Each issue comes with context: what happened, which documents are involved, what the emissions impact is in tonnes CO2-e, why it matters for compliance (NGER, ASRS, or both), and what to do about it. Related issues are grouped. Low-priority noise is suppressed below a configurable materiality threshold. Resolved issues are archived with a full audit trail - because your assurance provider will want to see not just that you found problems, but that you fixed them and documented how.
We won't pretend we've finished building this. Some of the harder resolution paths - particularly around Scope 3 data quality and multi-party joint venture allocations - are still works in progress. But the core thesis is simple: anomaly detection that doesn't lead to resolution is just a more sophisticated way of ignoring your data problems.
If you're currently staring at a screen full of unresolved alerts in whatever tool you're using, start with this: sort by emissions impact. Ignore everything below 5 tonnes CO2-e. That'll probably cut your 518 items down to about 30. Group those 30 by root cause - you'll likely find 5-8 actual issues. Fix those. That's your real data quality work. Everything else is noise pretending to be signal.