Agentic AI Workflows for Carbon Accounting
Most carbon tools call themselves AI-powered. Few run autonomously. Here's how Carbonly's verification, review, and anomaly agents work - and what they catch that humans miss.
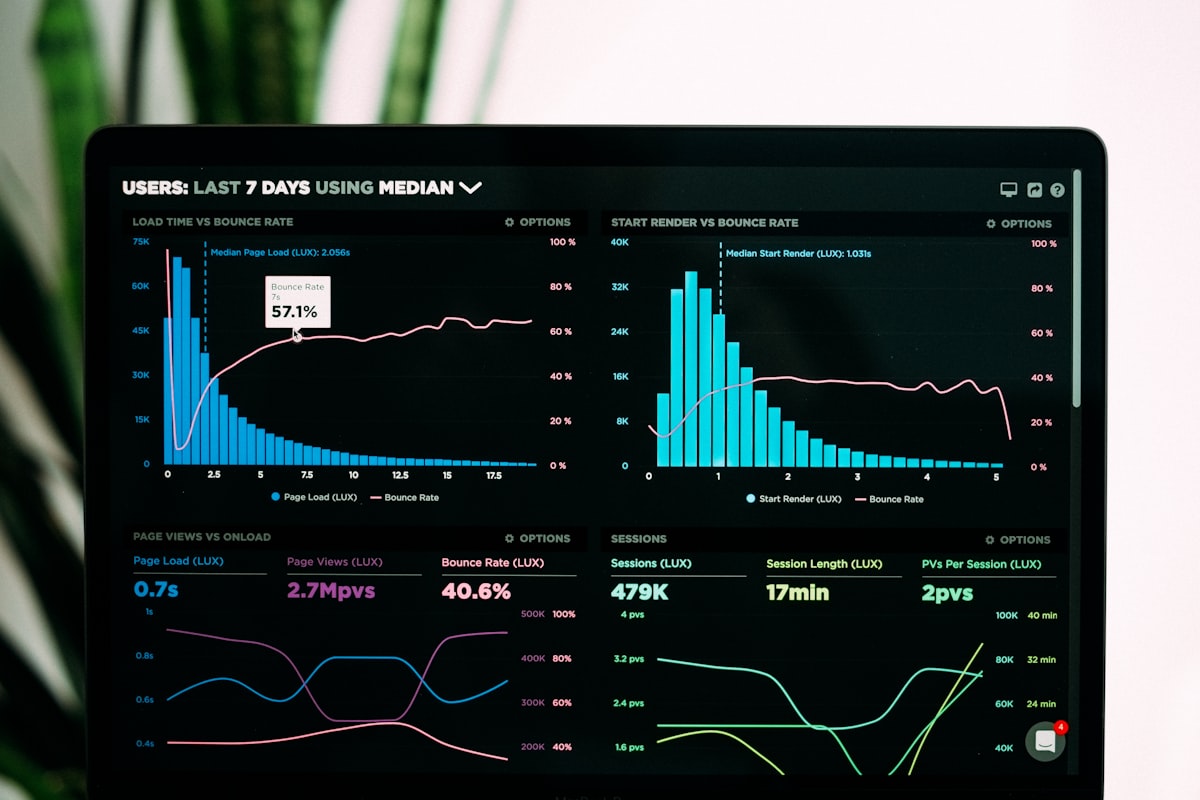
The ANAO found that 72% of NGER reports contained errors. Seventeen percent had significant ones. And the Clean Energy Regulator's enforcement action against Beach Energy in July 2025 made clear that "inadvertent misstatement" isn't a defence - it's a finding.
Most of those errors don't come from the maths. The emission factor calculation is multiplication. The errors come from the messy steps before and after: duplicate invoices nobody caught, a unit mismatch nobody noticed, a fuel docket counted twice because it sat in two folders, a quantity that should have triggered a question but didn't.
We've been building carbon accounting software long enough to know that the extraction step - pulling numbers from bills - gets all the attention. But the verification step, the review step, and the ongoing monitoring step are where data quality actually lives or dies. And those are the steps that almost nobody automates.
That's what agentic AI workflows are for. Not AI that assists. AI that acts - running checks, making decisions within defined boundaries, and flagging what needs human attention. Without waiting for someone to click a button.
The Difference Between "AI-Powered" and "Agentic"
There's a meaningful gap between an AI feature and an AI agent. Most carbon accounting platforms have AI features. Upload a bill, the AI reads it, you review the output. That's AI-assisted. A human initiates every action. The AI waits to be asked.
An agentic workflow is different. It runs on its own. It decides what to check. It applies rules. It escalates when something looks wrong. And it does all of this while you're doing something else entirely - or sleeping.
Gartner predicts that 40% of enterprise applications will embed AI agents by the end of 2026, up from less than 5% in 2025. In carbon accounting specifically, the shift matters more than most domains. Because the data quality problems in emissions reporting aren't the kind you solve by reading documents more accurately. They're the kind you solve by checking the output after it's been read - systematically, every time, without fatigue or shortcuts.
We built five agentic workflows into Carbonly. Each one targets a specific failure mode we kept seeing in real emissions data. Here's what they do and - just as important - where they still need a human.
The Verification Agent: Five Checks on Every Document
Every document that enters Carbonly goes through extraction first. The AI reads the bill, pulls out the consumption figure, identifies the material, matches an emission factor, and calculates emissions. That part we've written about before.
But extraction is just step one. The Verification Agent runs immediately after, applying five autonomous checks to every single result. No human triggers it. No button to click. It runs every time.
Content hash deduplication. The agent generates a fingerprint for every uploaded document. If the same file gets uploaded twice - which happens constantly when a site manager emails a bill and accounts payable also uploads it from the retailer portal - the agent catches it before it creates a duplicate emission record. This isn't fuzzy matching. It's exact. Same file, caught instantly.
Duplicate emission detection. This goes deeper than file-level deduplication. Two different documents can describe the same emission event. A fuel card CSV and a separate supplier invoice might both record 340 litres of diesel delivered to the same site on the same date. The agent compares material type, quantity, and date across all records in the project. If it finds a match, it flags it.
Why does this matter so much? Because duplicate emissions are the most common data quality failure we see. A company approaching the NGER 50 kt CO2-e corporate threshold could be pushed over - or under - by a few duplicated electricity bills across facilities. Getting this wrong has direct regulatory consequences.
Unit compatibility validation. This one catches a specific class of error that humans miss because it looks plausible. An extraction might return "450 litres" for what's actually an electricity bill. The unit is valid. The number is reasonable. But litres don't make sense for electricity - it should be kWh. The agent checks whether the extracted unit is compatible with the matched emission factor's expected unit. Litres against an electricity factor? Blocked.
Quantity outlier detection. The agent runs a statistical comparison against the previous 90 days of data for that source. If a site that typically uses 12,000-15,000 kWh per quarter suddenly shows 145,000 kWh, that's not necessarily wrong - maybe they commissioned new equipment. But it deserves a look. The agent flags it as an outlier without blocking it, so the reviewer sees it immediately.
Date sanity checking. Future dates get rejected outright. A billing period ending in 2027 on a document uploaded in March 2026 is a data entry error or an OCR misread. Dates more than 18 months old get flagged with a warning - not blocked, because late invoices are real, but highlighted so someone consciously decides to include them.
Each check produces one of three verdicts: Verified, Flagged, or Blocked. Verified means all five checks passed. Flagged means something needs human review but the data isn't necessarily wrong. Blocked means the agent has high confidence something is incorrect and won't let it through without intervention.
Every verdict - and every check that produced it - goes into an immutable decision log. When your ASRS auditor asks how you validated the Scope 2 figure for your Brisbane warehouse, you don't point to a person's memory. You point to a timestamped log showing five automated checks, the result of each, and who reviewed the flagged items.
That audit trail isn't a nice-to-have under AASB S2. It's what your auditor under ASSA 5010 will test. Did you have controls? Can you demonstrate them? The Verification Agent is a control. A documented, repeatable, auditable control.
The Bulk Review Agent: Turning Weeks Into Minutes
Here's a scenario we see all the time. A construction company uploads 400 fuel dockets, concrete delivery notes, and equipment hire invoices at the end of the quarter. The AI extracts the data. The Verification Agent runs its checks. Now there are 400 items sitting in a review queue, each needing someone to confirm the extraction, verify the emission factor match, and approve it into the emissions ledger.
At five minutes per document - and that's fast for a thorough review - you're looking at 33 hours. More than four full working days, doing nothing but clicking through review screens.
The Bulk Review Agent changes this completely.
You select the pending documents you want reviewed - all 400, or a filtered subset. You choose a trust level: review-only (the agent reviews but doesn't confirm anything, so you see its assessment) or review-and-confirm (the agent reviews AND auto-confirms results that pass all checks above a confidence threshold you set).
Then the agent runs. It re-examines every extraction. It re-matches materials against the emission factor library. It re-runs the verification checks. For high-confidence results - clean digital bills from known retailers, fuel card CSVs with unambiguous data, utility invoices from formats the system has seen hundreds of times - it confirms them directly into the emissions ledger. No human touch needed.
For anything below the confidence threshold, it leaves the item in the queue with its assessment attached. Your reviewer doesn't start from scratch. They start from the agent's analysis: "This looks like 28MPa GP concrete, matched to NGA factor X at Tier 2 (alias match from previous confirmation), confidence 88%. Flagged because quantity is 15% above 90-day average for this site."
The result? Those 33 hours collapse. The agent handles the straightforward 80-85% autonomously. Your reviewer spends their time on the 15-20% that actually needs human judgement. We're not going to claim an exact time saving because it depends on your document mix and confidence thresholds. But the difference between reviewing 400 items and reviewing 60-80 flagged items is the difference between a week of work and a morning.
We built concurrent run protection into this too. If one team member kicks off a bulk review and another tries to start one on the same project, the system prevents it. And if a bulk review stalls mid-run - network timeout, system restart, anything - the recovery mechanism picks up where it left off rather than starting over or leaving records in a half-confirmed state.
The Anomaly Scan Agent: Catching What Review Missed
The Verification Agent checks data at the point of entry. The Bulk Review Agent handles the confirmation workflow. But what about data that's already been confirmed and sitting in your emissions ledger?
That's the Anomaly Scan Agent's job. It runs across your confirmed emission records - the data you've already reviewed and approved - looking for patterns that individual-document review doesn't catch.
It runs eight checks.
Duplicate records that slipped through initial verification - maybe because they were uploaded weeks apart and the earlier deduplication window didn't catch them. Statistical outliers against the full historical dataset, not just the 90-day window the Verification Agent uses. Missing data - gaps in what should be a continuous series of monthly electricity bills for a site. Unit mismatches that are subtler than the obvious ones - like a Scope 2 emission calculated using a Scope 3 factor. Cross-document date conflicts - two bills for the same meter with overlapping billing periods. Stale emission factors - records calculated using last year's NGA factors when this year's have been published. Missing scope classification - emission records that weren't assigned to Scope 1, 2, or 3. And suspicious quantity-to-emission ratios - a record where the relationship between the activity data and the calculated emission doesn't align with what the factor should produce, suggesting a conversion error.
That last one is worth explaining. Say you've got a record showing 500 litres of diesel producing 50 tonnes of CO2-e. Diesel at roughly 2.7 kg CO2-e per litre should produce about 1.35 tonnes, not 50. Something went wrong in the calculation - maybe a unit conversion multiplied by 1,000 instead of dividing. A human reviewer who approved the individual record might not catch it because the number looks plausible in isolation. The anomaly scan catches it because it checks the ratio.
We're not sure the eight checks we have today are the right final set. We keep adding checks as we discover new failure patterns in real data. But these eight catch the majority of post-confirmation errors we've observed.
The scan results feed into a report that your sustainability manager can review periodically - monthly, quarterly, or before the NGER 31 October deadline. Think of it as a health check on your emissions dataset. The kind of thing the ANAO wished NGER reporters were doing when they found those error rates.
Carbonly Co-Pilot: Ask Your Data Questions in Plain English
The agents above run autonomously. The Co-Pilot is different - it's interactive. But it belongs in this discussion because it uses the same underlying intelligence against the same dataset.
Ask it a question in plain English: "What were our total Scope 2 emissions for the Melbourne warehouse last financial year?" And it answers. Not from a pre-built report. Not from a dashboard you have to navigate. From the actual emission records in your account, filtered by scope, site, and date range.
It understands Australian financial year conventions. "This FY" means July to June. "Last quarter" means Q2 FY2025-26 if you're asking in March 2026. These seem like small things, but anyone who's built reporting tools for Australian businesses knows that date handling is where half the data discrepancies originate.
The Co-Pilot covers every module in the platform. Ask about your targets and it tells you where you stand. Ask about a specific material and it shows you the emission factor, the source, and every record where that material appears. Ask about incidents, anomalies, projects - it pulls from all of them.
This matters most during audit preparation. When your auditor asks "how did you determine the emission factor for refrigerant top-ups at Site 14?" - instead of searching through spreadsheets or scrolling through dashboards, you ask the Co-Pilot. It returns the factor, its source (NGA Factors 2025, Table 39, R-410A, GWP 2,088), the document it was extracted from, and the verification verdict.
We should be clear about what the Co-Pilot doesn't do. It doesn't generate qualitative narrative for your AASB S2 disclosure. It doesn't write your transition plan. It doesn't interpret scenario analysis results for you. It answers factual questions about your emissions data. That's its scope - deliberately narrow, deliberately reliable.
Self-Learning Material Matching: Your Second Quarter Is Faster Than Your First
This isn't a standalone agent in the same sense as the others. It's a capability that runs through the entire system and gets better over time. But it's worth explaining because it's what makes the gap between "AI tool" and "agentic system" feel real in daily use.
When the system encounters a line item it hasn't seen before - say, "AdBlue DEF 210L" on a construction fuel receipt - it runs through the 5-tier matching process to find the right emission factor. AdBlue (diesel exhaust fluid) is urea-based, not a hydrocarbon fuel. It shouldn't be matched to a diesel emission factor. The system needs to recognise it as a chemical input with its own factor profile.
When a user confirms or corrects that match, the system stores the association. Not just "AdBlue = this factor," but "AdBlue from this supplier = this factor, confirmed by this user on this date." That's a Supplier-Product Mapping (SPM). Next time a document from the same supplier mentions AdBlue, the system matches it instantly at Tier 2 instead of running through the full matching chain.
Scale that across every material, every supplier, every correction across every user in the organisation. By your second reporting quarter, the system has seen most of your common documents and materials before. Match rates climb. Confidence scores improve. The number of items flagged for review drops. Not because the system is lowering its standards - the thresholds stay the same - but because it's matching with higher accuracy.
We've seen organisations go from roughly 40% Tier 1 (exact) matches in their first month to over 70% combined Tier 1 and Tier 2 matches within a few quarters, as the alias library fills with their specific supplier names, product descriptions, and invoice formats. Each confirmed match is a permanent improvement. Every correction trains the system.
Consider a construction company processing 10,000 fuel receipts per quarter across diverse materials - diesel, unleaded, LPG, AdBlue, concrete at various mix strengths, reinforcing steel, timber, aggregate. In the first quarter, many of these are new to the system. By the third quarter, the vast majority match automatically at high confidence. The review workload shrinks progressively - not because you're checking less, but because there's less to check.
What This Means for NGER and ASRS Compliance
Let's connect these agents to the regulatory reality Australian businesses face.
NGER reports are due 31 October. Every year. No extensions. The Clean Energy Regulator has demonstrated through the Beach Energy enforceable undertaking that data quality failures carry real consequences - three years of mandatory reasonable assurance audits and a public undertaking for "inadvertent misstatement." The ANAO's audit finding that 72% of reports contained errors should worry every reporter relying on manual processes.
ASRS Group 2 reporting started from financial years beginning 1 July 2026. Group 3 starts from 1 July 2027. Under AASB S2, your climate disclosures face assurance - limited assurance from year one under ASSA 5010, progressing toward reasonable assurance. Auditors will test whether your data collection process has appropriate controls.
An agentic workflow is a control. A documented, automated, auditable control. The Verification Agent's decision log proves that every document was checked for duplicates, unit compatibility, outliers, and date validity. The Bulk Review Agent's confirmation records prove that each emission was reviewed (by the agent, by a human, or both) before entering the ledger. The Anomaly Scan Agent's reports prove that you periodically validated the integrity of your confirmed dataset.
That's a fundamentally different compliance posture than "our sustainability analyst checked the spreadsheet." The ACCC has made clear that inaccurate environmental claims carry penalties up to $50 million for listed corporations. Your emissions numbers need to be right. And "right" means auditable, not just plausible.
The Honest Gaps
We'd be dishonest if we said these agents solve everything. They don't.
Scope 3 remains genuinely difficult. The Verification Agent can check for duplicates and outliers in supplier data, but it can't fix the underlying accuracy problem when a supplier provides spend-based figures with 30-40% error margins. Automating the processing of inaccurate data gives you faster inaccuracy. We flag the confidence level and data source so your team knows which Scope 3 figures are solid and which are estimates - but we won't pretend the automation fixes what's fundamentally a data availability problem.
The Anomaly Scan Agent's eight checks are good, but they're not exhaustive. We keep discovering new failure patterns. Methane reporting for landfill operators, for instance, involves engineering judgement calls (First Order Decay model parameters, climate-zone k-values) that a statistical outlier check won't catch. Industry-specific emissions have industry-specific failure modes that generic checks miss.
And the self-learning loop has a cold-start period. Your first quarter will still require meaningful human review effort as the system builds its material library from your specific data. The productivity gains are real, but they compound over time rather than appearing on day one.
We're also still working through the boundary between "agent should decide" and "human must decide." Where exactly should the confidence threshold sit for auto-confirmation? How aggressive should outlier detection be before it creates alert fatigue? These are configuration decisions that depend on your risk tolerance and your auditor's expectations. We provide defaults that work for most reporters, but the right settings for a mining company reporting under the Safeguard Mechanism are different from a property manager tracking Scope 2 across 50 sites.
What to Do With This
If you're preparing for your next NGER deadline or your first ASRS disclosure, the practical question isn't whether AI can help with carbon accounting. It can. The question is whether the AI runs autonomously - checking, verifying, and flagging - or whether it just sits there waiting for someone to push buttons.
Start with your highest-volume data source. For most companies, that's electricity bills or fuel receipts. Upload a quarter's worth. Watch what the Verification Agent catches. Run the Bulk Review Agent on the results. Then run the Anomaly Scan after confirmation.
The errors it finds in data you thought was clean will tell you more about the value of agentic workflows than anything we could write here.
Related reading:
- The 7-Phase AI Pipeline That Reads Your Utility Bills - how each extraction phase works and where it breaks
- Emission Factor Matching: The Part of Carbon Accounting AI Actually Needs to Solve - the 5-tier matching system and why factor selection causes more errors than extraction
- NGER Compliance: What the Clean Energy Regulator Actually Checks - enforcement patterns, Beach Energy, and why data quality matters
- ASRS Assurance: What Your Auditor Will Ask For - ASSA 5010, audit trail requirements, and how to prepare